# Long-Context Isn't the Answer
Kyle · March 23, 2026 · < 7 min read
Anthropic just switched the default model in Claude Code to Opus 4.6 with a 1M context window. We tried it when it launched. But now we're switching back to Opus 4.5
## How about some context?
Unlike previous Claude Opus models which have a ~ 200k context window, Opus 4.6 has as 1M context window. This was very exciting for us!
We spend a lot of time working on hard problems in large enterprise codebases, and if the model can reliably hold more of the codebase in its head at a time, so to speak, then that creates new possibilities for the scale of problem that can be solved in a single context window.
It would mean less compaction (whether frequent intentional compaction or auto-compact), and less "context pressure" to solve the problem before your context window fills up.
As Calvin French-Owen, who helped launch Codex last year, puts it in an episode of YC's Lightcone podcast:
...imagine you're a college student. You're taking an exam. In the first five minutes of that exam, you're like, "Oh, I have all the time in the world. I'll do a great job. I'll think through each of these problems."
Let's say you have like five minutes left and you still have half the exam left. You're like, "Oh man, I just got to do whatever I can." Like, that's the LLM with a context window
## More context, less instruction adherence
While the context window is dramatically larger, we noticed over the course of a couple of weeks that instruction adherence was dramatically degraded, and not just at longer context lengths.
Even well-within what we would consider the smart zone of a 200k-context frontier model, the model was less precise. It would ignore design documents and other inputs when writing a plan file. It would make trivial mistakes, or misunderstand simple instructions - or worse, directly disobey them.
At longer context lengths, the degradation was even steeper - like the user instructions were getting drowned out by the intermediate tool results and mass of accumulated context.
## What determines instruction adherence?
We've written about the concept of the instruction budget before - a measurable property of LLMs which describes how many instructions they can follow reasonably well before instruction adherence drops off.
It's different for each model, but it's a function primarily of the quality of the model's instruction tuning, and more importantly for our purposes, it is strongly correlated with the size of the model.
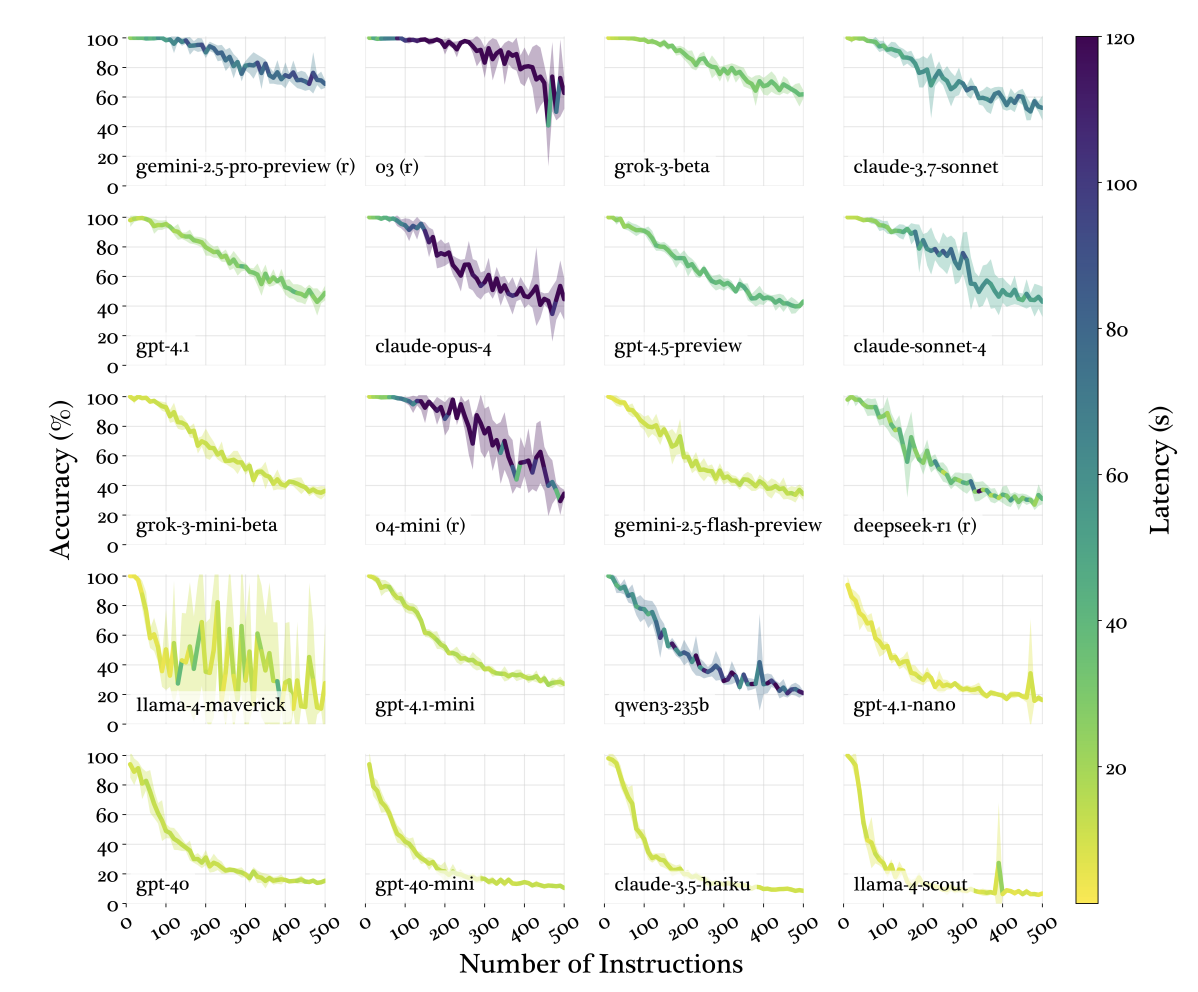
You can clearly see that the larger models from the study can follow dramatically more instructions before adherence drops off.
## Instruction adherence at long context lengths
Why does this matter?
When a lab offers an extended-context version of a model, you're usually not getting a bigger model with more parameters and therefore a larger "instruction budget" to go with the larger context window - you're likely getting the same model with some clever math (e.g. YaRN) to extend the sequence length the model can attend to, and probably some more post-training to stabilize the model at the longer sequence lengths.
This means that while the context window size increases, the instruction budget remains the same. You can fit more context and more instructions in the context window, but the model isn't actually better at attending to those instructions over the context length.
## Instruction-following as needle in a haystack
You can think of your context window as a haystack where all of your tool calls and documents and files are hay - every line in your CLAUDE.md file, every instruction in your tool descriptions, every tool result, every instruction in your system prompt, and every user message.
The quality & correctness of the agent's next step depends on the LLM's ability to find a needle in there: namely, the instruction(s) in the context window that are most-relevant to the current state of the context window, which give it the information it needs to make the correct decision about its next action.
Now imagine we increase the size of the haystack by 500% - but the size of the needle remains the same. Unless our ability to find the needle also increases by 500%, we will have a dramatically harder time finding it. The extra context isn't really helping us - it's just digging us deeper into the dumb zone.
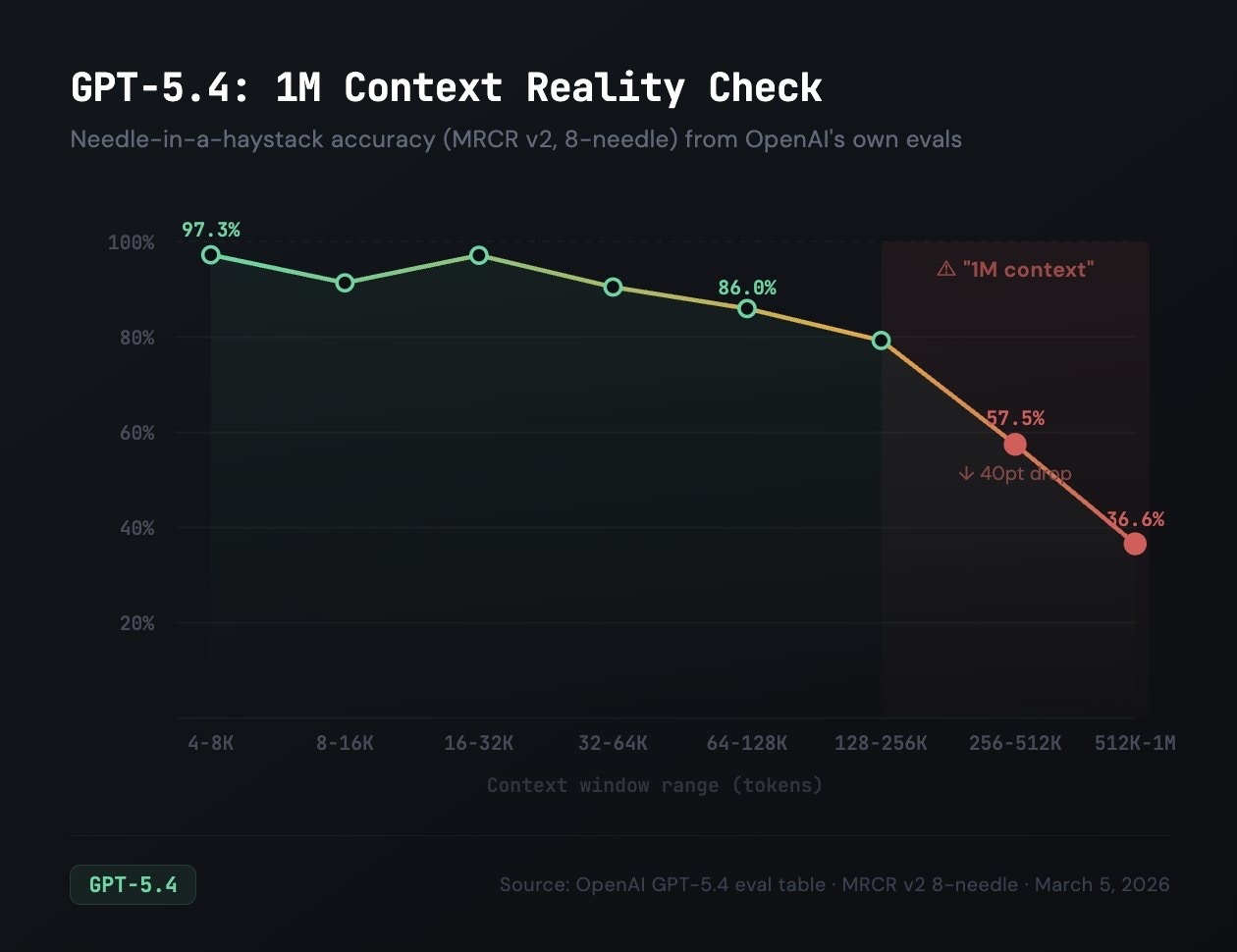
## What Works Instead
Instead of trying to stuff as much information in a context window as possible and having the LLM reason over it, we found that the context management techniques we had been using had to be used even more aggressively to keep Opus 4.6 1M on track.
In my post on harness engineering, I wrote about this as the limit case for using sub-agents:
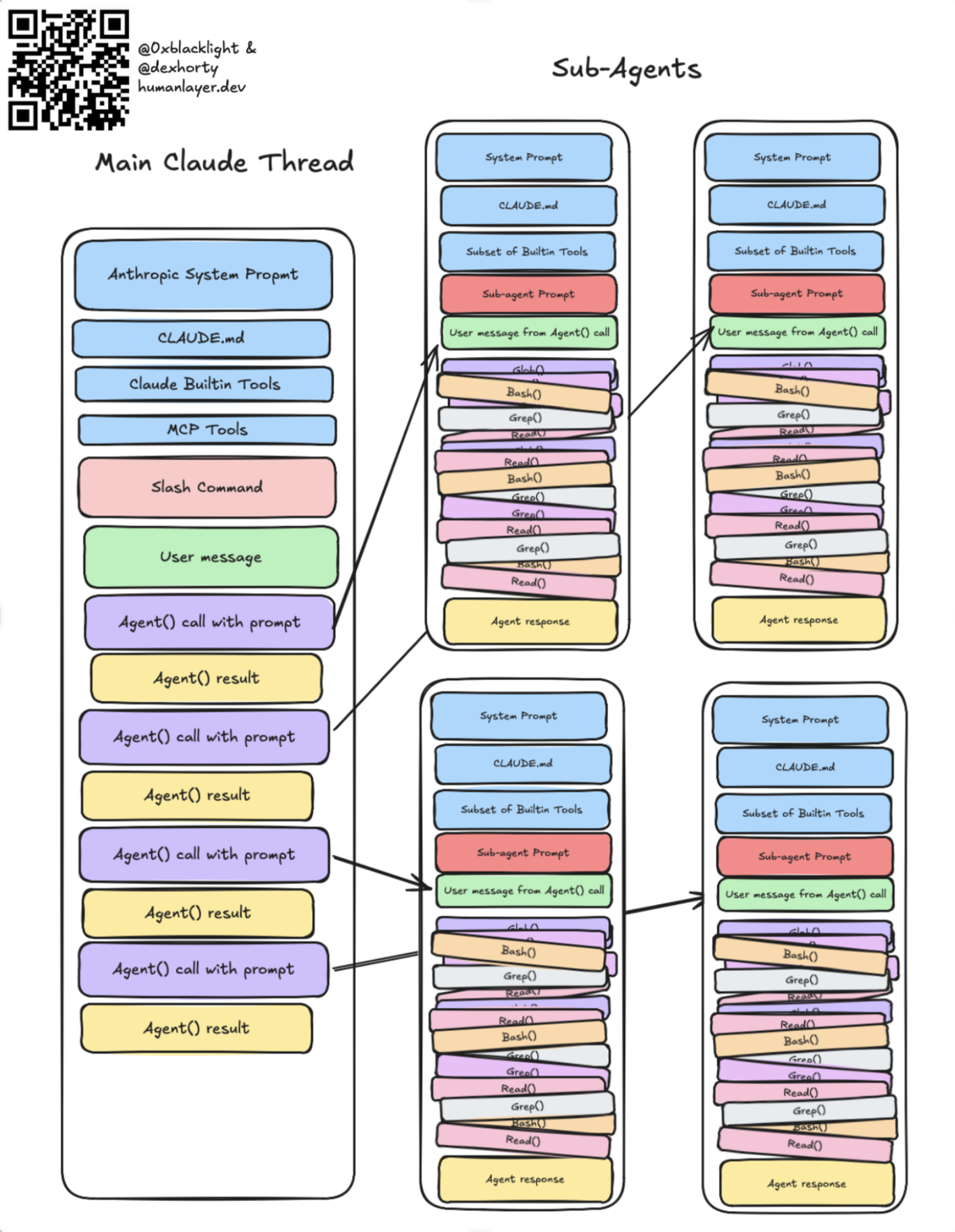
The day after I published it, I decided maybe it wasn't such a bad idea, and sat down and wrote this skill:
--- name: subagent-orchestrator description: orchestrate sub-agents to accomplish complex long-horizon tasks without losing coherency by delegating to sub-agents --- This skill provides you with **CRITICAL** instructions that will help you to maintain coherency in long-horizon context-heavy tasks. You have a large number of tools available to you. The most important one is the one that allows you to dispatch sub-agents: either `Agent` or `Task`. All non-trivial operations should be delegated to sub-agents. You should delegate research and codebase understanding tasks to codebase-analyzer, codebase-locator and pattern-locator sub-agents. You should delegate running bash commands (particularly ones that are likely to produce lots of output) such as investigating with the `aws` CLI, using the `gh` CLI, digging through logs to `Bash` sub-agents. You should use separate sub-agents for separate tasks, and you may launch them in parallel - but do not delegate multiple tasks that are likely to have significant overlap to separate sub-agents. IMPORTANT: if the user has already given you a task, you should proceed with that task using this approach. If you have not already been explicitly given a taks, you should ask the user what task they would like for you to work on - do not assume or begin working on a ticket automatically.
I found that using this skill in combination with our existing workflow skills helped me keep Opus coherent at longer context lengths. Why? As I wrote about in that post, sub-agents encapsulate context and ensure that only highly-relevant context (the prompt, and the focused sub-agent result) end up in the context window, avoiding context rot:
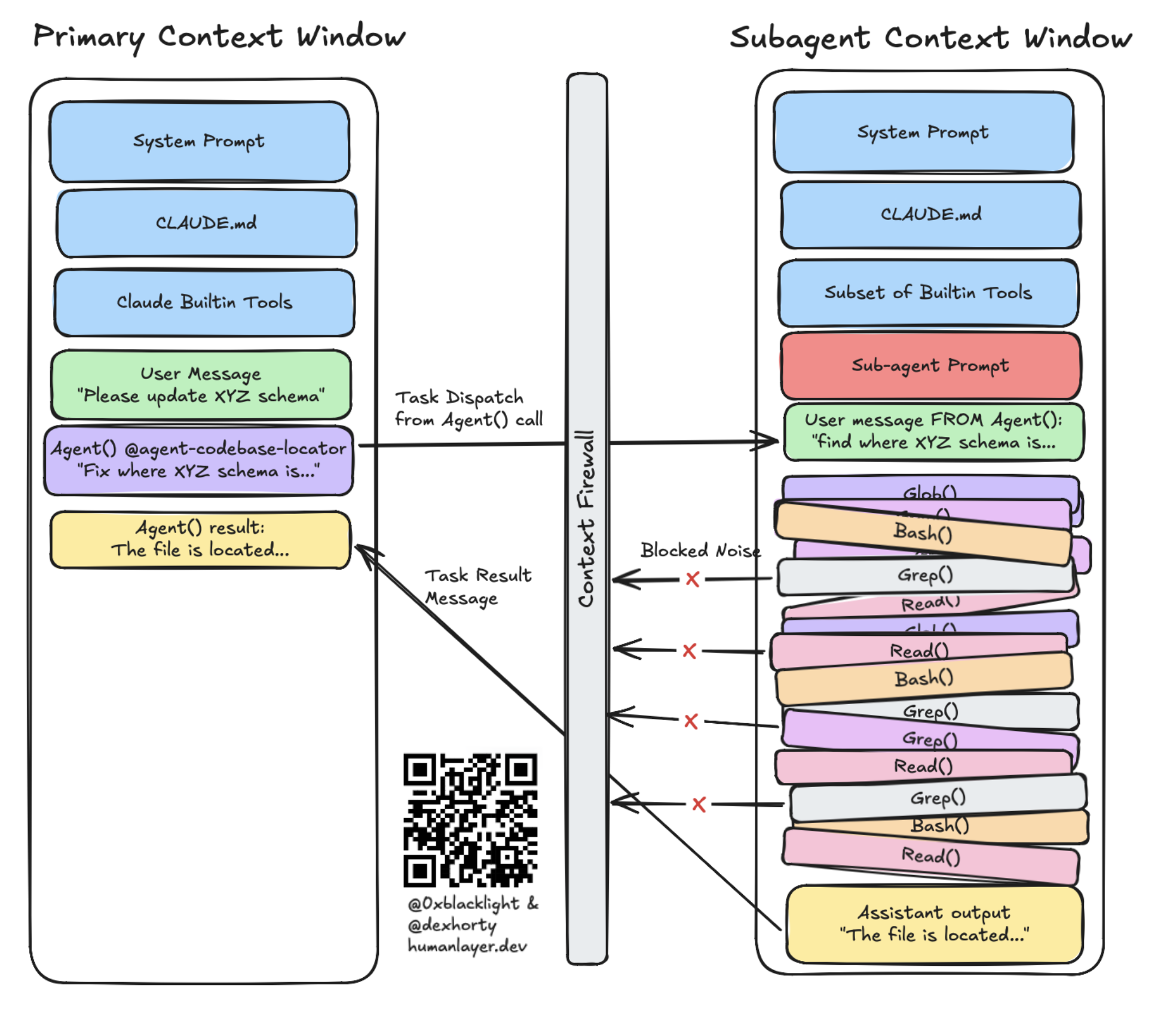
## How we're incorporating this at HumanLayer
We have had a feature in the tool for a while that warns the user when they're context is getting high. We used to set this at around %40 of sonnets 168k token window (200k - 32k reserved for output). This came out to about 100k tokens.
To help users maximize instruction adherence and intelligence on hard codebase problems, we've updated our context warnings for long-context models to trigger at the 100k token mark instead of 40% of the usable context. For opus 1m this is only 10% of the context window.
## TL;DR
- Long-context models degrade at all context lengths, not just long ones.
- More context isn't more capability - the instruction budget doesn't scale with the context window.
- Context isolation beats context expansion. Sub-agents, progressive disclosure, and context-efficient backpressure keep each context window small, focused, and in the smart zone.